Tutoriels de Pythonia
Guides, IA, tutos et newsletter pour devenir une bête en programmation
🎂 Obtenez le code source de ce tutoriel !
Recevez le code directement dans votre boîte mail.
Recevez le code directement dans votre boîte mail.
Mis à jour le June 25, 2024, 6:43 a.m.
GPT-4 avec vision permet de décrire et comprendre le contenu d’images extraites de vidéos. Cela ouvre la voie à de nombreuses applications : résumé automatique, surveillance intelligente, création de métadonnées ou encore chapitrage de vidéos.
Dans ce tutoriel, nous allons voir comment utiliser GPT-4 Vision pour analyser une vidéo image par image avec Python. L’objectif est d’extraire automatiquement des descriptions de scènes ou d’actions à partir d’une vidéo locale.
Prérequis
Extraction des images de la video
Envoi des images à GPT4-vision
Génération de notre audio
Conclusion
FAQ
Python 3.10+
Une clé API OpenAI valide
Les bibliothèques suivantes
Comme d'habitude, on crée un virtualenv si vous n'en avez pas déjà un.
mkvirtualenv openai
Puis on installe les librairies suivantes:
pip install openai opencv-python python-dotenv requests
Optionnel: si vous voulez masquer votre clé API Openai, créez un fichier .env à la racine de votre projet, et insérez la ligne suivante.
OPENAI_API_KEY=votre_clé_api
Faisons naivement un premier test avec ce code:
import os
load_dotenv()
key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=key)
video = cv2.VideoCapture("/home/pythonia/Vidéos/2025-03-24 16-50-25.mkv")
# Extract frames from video
base64Frames = []
while video.isOpened():
success, frame = video.read()
if not success:
break
_, buffer = cv2.imencode(".jpg", frame)
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
video.release()
print(len(base64Frames), "frames read.\n")
# Create chat prompt
PROMPT_MESSAGES = [
{
"role": "user",
"content": [
"These are frames from a video that I want to depict. Explain what is in the video in a summary paragraph.",
*map(lambda x: {"image": x, "resize": 768}, base64Frames[0::30]),
],
},
]
params = {
"model": "gpt-4o",
"messages": PROMPT_MESSAGES,
"max_tokens": 300,
}
result = client.chat.completions.create(**params)
print(result.choices[0].message.content)
On obtient l'erreur suivante si votre video suivante:
2058 frames read.
Traceback (most recent call last):
File "/home/pythonia/gpt4_vision.py", line 43, in <module>
result = client.chat.completions.create(**params)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/pythonia/.virtualenvs/openai/lib/python3.12/site-packages/openai/_utils/_utils.py", line 279, in wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/pythonia/.virtualenvs/openai/lib/python3.12/site-packages/openai/resources/chat/completions/completions.py", line 914, in create
return self._post(
^^^^^^^^^^^
File "/home/pythonia/.virtualenvs/openai/lib/python3.12/site-packages/openai/_base_client.py", line 1242, in post
return cast(ResponseT, self.request(cast_to, opts, stream=stream, stream_cls=stream_cls))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/pythonia/.virtualenvs/openai/lib/python3.12/site-packages/openai/_base_client.py", line 919, in request
return self._request(
^^^^^^^^^^^^^^
File "/home/pythonia/.virtualenvs/openai/lib/python3.12/site-packages/openai/_base_client.py", line 1008, in _request
return self._retry_request(
^^^^^^^^^^^^^^^^^^^^
File "/home/pythonia/.virtualenvs/openai/lib/python3.12/site-packages/openai/_base_client.py", line 1057, in _retry_request
return self._request(
^^^^^^^^^^^^^^
File "/home/pythonia/.virtualenvs/openai/lib/python3.12/site-packages/openai/_base_client.py", line 1008, in _request
return self._retry_request(
^^^^^^^^^^^^^^^^^^^^
File "/home/pythonia/.virtualenvs/openai/lib/python3.12/site-packages/openai/_base_client.py", line 1057, in _retry_request
return self._request(
^^^^^^^^^^^^^^
File "/home/pythonia/.virtualenvs/openai/lib/python3.12/site-packages/openai/_base_client.py", line 1023, in _request
raise self._make_status_error_from_response(err.response) from None
openai.RateLimitError: Error code: 429 - {'error': {'message': 'Request too large for gpt-4o in organization org-elZ8r3Bj2cITtaJdZdMtlgcz on tokens per min (TPM): Limit 30000, Requested 52814. The input or output tokens must be reduced in order to run successfully. Visit https://platform.openai.com/account/rate-limits to learn more.', 'type': 'tokens', 'param': None, 'code': 'rate_limit_exceeded'}}
Cela signifie que notre requête dépasse la limite de tokens par minute (TPM) autorisée par OpenAI.
Chaque image encodée en base64 peut consommer plusieurs milliers de tokens. Si vous envoyez trop d'images dans une même requête, vous dépassez rapidement la limite.
Comment faire alors? Il suffit de réduire la résolution des images.
Utilisons OpenCV pour manipuler notre video, et donc nos images(ici pour les bases si vous ne connaissez pas opencv). Même si on demande un resize: 768, ça ne diminue pas vraiment la taille base64 (ce paramètre sert plus à l'affichage, côté OpenAI).
On va reduire les frames avant encodage, en faisant par exemple:
frame = cv2.resize(frame, (320, 180)) # ou même 224x224
On peut même compresser les images comme ça:
_, buffer = cv2.imencode(".jpg", frame, [int(cv2.IMWRITE_JPEG_QUALITY), 50])
Voici le code qui permet d'envoyer notre video dans OPENAI.
import os, base64
import cv2
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=key)
video = cv2.VideoCapture("/home/pythonia/Vidéos/2025-03-24 16-50-25.mkv")
base64Frames = []
while video.isOpened():
success, frame = video.read()
if not success:
break
# Resize + compression
frame = cv2.resize(frame, (320, 180))
_, buffer = cv2.imencode(".jpg", frame, [int(cv2.IMWRITE_JPEG_QUALITY), 50])
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
video.release()
print(len(base64Frames), "frames read.\n")
# Send fewer frames
frames_to_send = base64Frames[0::90] # Extrait environ 22 images
PROMPT_MESSAGES = [
{
"role": "user",
"content": [
"Ce sont des images extraites d'une vidéo que je souhaite décrire. Explique ce que montre la vidéo dans un paragraphe de résumé.",
*map(lambda x: {"image": x, "resize": 768}, frames_to_send),
],
},
]
params = {
"model": "gpt-4o",
"messages": PROMPT_MESSAGES,
"max_tokens": 300,
}
result = client.chat.completions.create(**params)
print(result.choices[0].message.content)
GPT-4 fournira une description textuelle de chaque image. Vous pouvez stocker ces réponses, générer un résumé global, ou créer des métadonnées associées à chaque moment clé.
Pour une vidéo longue, il est recommandé de réduire la résolution des images pour accélérer le traitement.
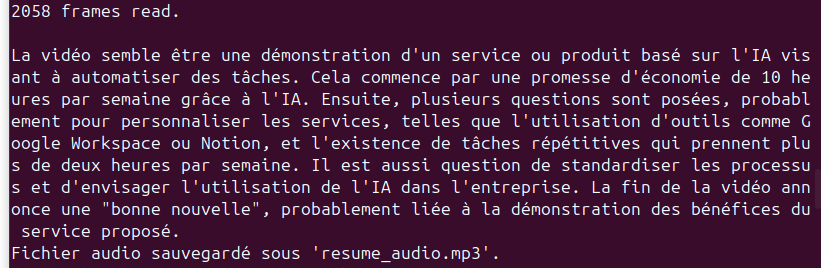
Voilà le résultat:

Super, il ne nous reste plus qu'à générer notre audio.
response = requests.post(
"https://api.openai.com/v1/audio/speech",
headers={
"Authorization": f"Bearer {key}",
},
json={
"model": "tts-1-1106",
"input": result.choices[0].message.content,
"voice": "onyx",
},
)
audio = b""
for chunk in response.iter_content(chunk_size=1024 * 1024):
audio += chunk
Audio(audio)
Voilà le résultat, notre audio a été généré et sauvegardé.
GPT-4 Vision facilite grandement l’analyse de vidéos en automatisant la compréhension d’images.
Avec quelques lignes de Python, vous obtenez une analyse scène par scène, utile pour la création de contenu, la documentation ou la surveillance intelligente.
Pour ceux qui veulent s'amuser il y a quelques idées d'améliorations supplémentaires:
Générer une vidéo avec audio + images synchronisées ?
Q: Est-ce que ça fonctionne avec des vidéos longues ?
R: Oui, mais il faut limiter le nombre d’images analysées pour rester dans les limites de l’API.
Q: GPT-4 Vision peut-il détecter des objets spécifiques ?
R: Oui, vous pouvez orienter le prompt pour demander la présence de certains objets ou actions.
Q: Est-ce que l’analyse est rapide ?
R: Oui, mais cela dépend du nombre d’images et de la taille des fichiers.
Q: L’analyse peut-elle être en temps réel ?
R: Pas pour l’instant, mais avec des optimisations et un système en file d’attente, c’est envisageable.
https://openai.com/index/hello-gpt-4o/
https://github.com/openai/openai-cookbook/
Aucun commentaire pour ce tutoriel.
Soyez le premier à réagir !